
Commentary: It's no longer exciting to talk about the rise of non-relational databases, but it's happening all the same.

Image: iStock/GaudiLab
It's not exactly clear where we are in the Gartner Hype Cycle with respect to so-called "NoSQL" databases. We've definitely been through the Trough of Disillusionment, but are we in the Slope of Enlightenment or have graph, document, key-value and other such databases hit the mainstream (Plateau of Productivity)? My sense is that we're at the front end of mainstream adoption given how quiet the media has gone on databases like Redis, Neo4j and MongoDB, despite their rising popularity.
In other words, non-relational databases have never been more popular, or more invisible in that popularity. Until Neo4j's $325 million fund raise we'd all but forgotten databases at all, preferring to focus on shiny, new options (Snowflake, anyone?). But it's precisely at this moment when databases have become uninteresting to talk about that they're most interesting from an adoption perspective. Let's take a look.
SEE: Navigating data privacy (free PDF) (TechRepublic)
Tip of the data iceberg
Unfortunately, we don't have a lot of public data to work with. Yes, we have MongoDB's revenue data (up 39% year-over-year, with a rising percentage shifting to cloud), but even here we don't have the full story. We know, for example, that the company now has over 25,000 customers, but this leaves out the tens of thousands (or hundreds of thousands?) more that download the software and run MongoDB in their on-premises data center or self-host it with one of the cloud providers. MongoDB has reported that the database was downloaded over 70 million times last year, which is even more impressive when you consider that it has been downloaded 175 million times (cumulative) since 2007.
In other words, the popularity of MongoDB is accelerating. Fast.
Given the data in DB-Engines' popularity rankings, MongoDB isn't alone in this among the non-relational database crowd. We don't know, for example, what Neo4j's revenue is, but we do know its VCs saw enough promise to fund the biggest database venture capital raise in history. So let's look at the data that we do have.
First, it's clear that relational databases continue to dominate the data landscape, with Oracle, MySQL, SQL Server and PostgreSQL continuing to top the charts. But this tells an incomplete story–it basically tells us where the market has been, not where it's going. If we take a different view of the data, we see non-relational databases spiking in popularity, relative to their relational database peers (Figure A).
Figure A
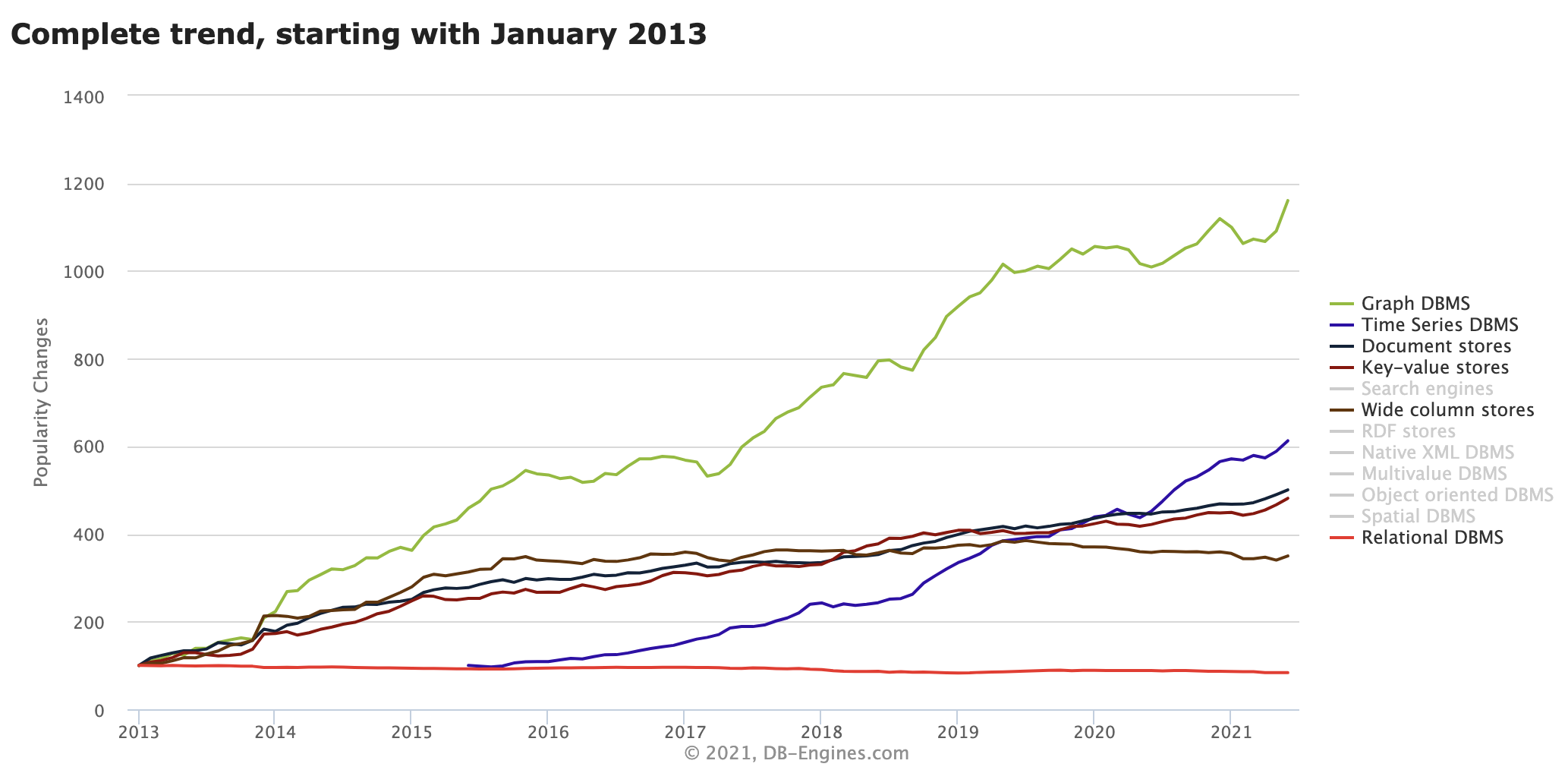
Image: DB-Engines
This becomes even more pronounced (and nuanced) if we look at just the past 24 months (Figure B).
Figure B
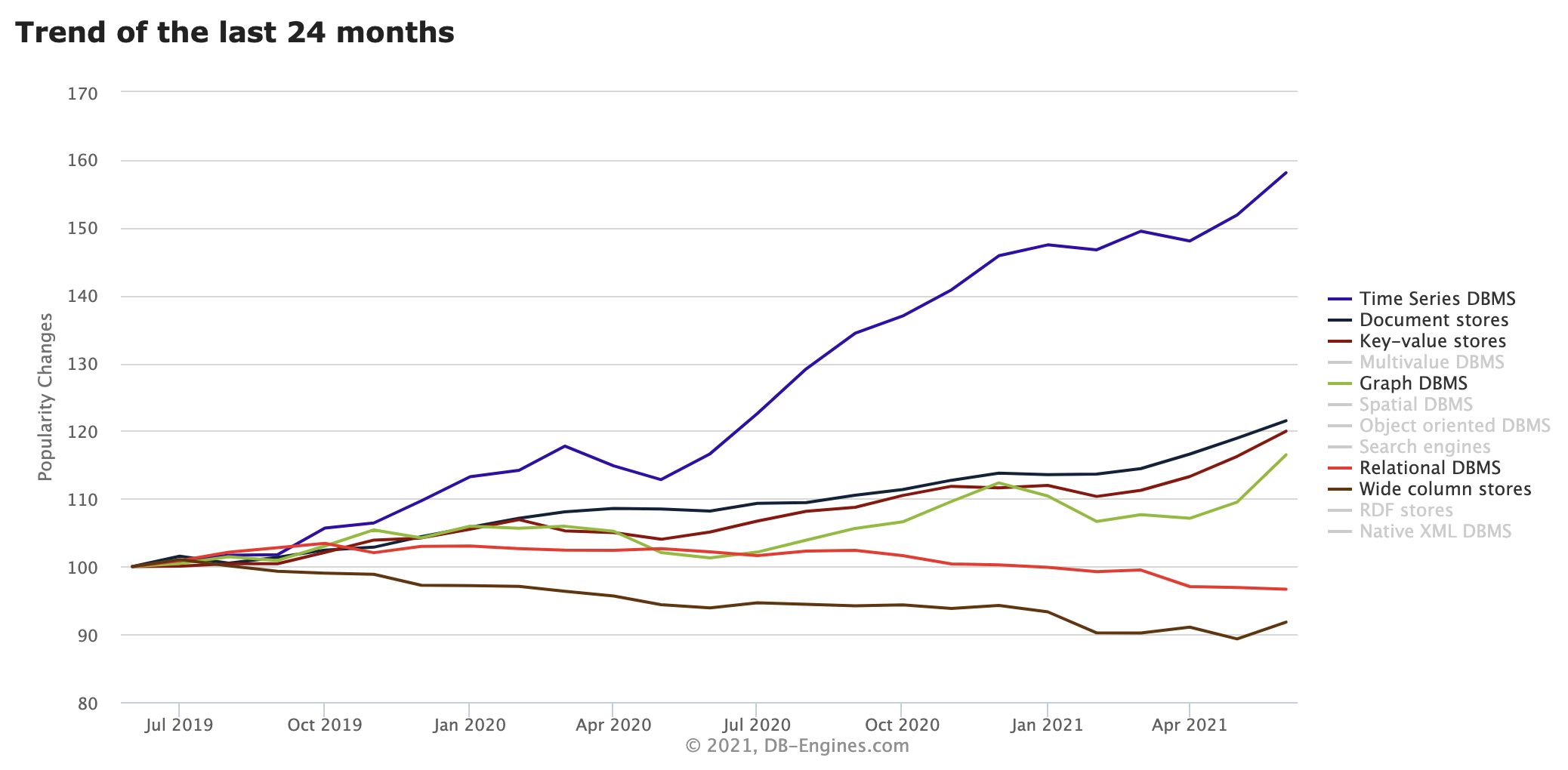
Image: DB-Engines
Keep in mind that these charts measure relative popularity, not absolute. In terms of absolute popularity, relational databases collectively garner 72.8% of the total. Graph databases? 1.7%. Time series, which shows such a pronounced leap in this last chart? Just 0.9%.
But document databases, which are largely represented by just one database (MongoDB), come in at 10%. That's a significant slice of the overall database pie, and growing fast.
It's a bit like cloud, in a way. Cloud is growing fast, but it still represents just 5-6% of overall IT spending. Yet, as IDC vice president Stephen Minton has noted, "Where there is growth, most of it is in the cloud." The same is true in databases. Relational is where the market is, but it's not where the growth in the market is. That growth is in non-relational databases. Both are going to coexist for some time and probably forever. (After all, mainframes are ever with us. IT doesn't die–it just stops growing relative to the rest of the market.)
So, yes, the non-relational database market is booming, and will continue to do so. Minton, again: "The amount of data that companies must store and manage is not going anywhere. Increasingly, even more of that data will be stored, managed, and increasingly also analyzed in the cloud." The cloudier the data, the more it assumes the "three Vs" (volume, velocity, variety) of "big data," and much of that keeps finding its way into MongoDB, Prometheus, InfluxDB, Redis, Apache Cassandra and other non-relational databases. We don't necessarily talk about it, but it's happening, all the same.
Disclosure: I work for AWS, but the views expressed herein are mine, not those of my employer.

Data, Analytics and AI Newsletter
Learn the latest news and best practices about data science, big data analytics, and artificial intelligence. Delivered Mondays
Sign up todayAlso see
What's the secret to database success? The answer may surprise you (TechRepublic)
- Postgres is hot, but developers haven't lost their love for MySQL. Here's why (TechRepublic)
How to succeed in software engineering management (TechRepublic)
How to become a data scientist: A cheat sheet (TechRepublic)
Big data's role in COVID-19 (free PDF) (TechRepublic download)
Power checklist: Local email server-to-cloud migration (TechRepublic Premium)
Volume, velocity, and variety: Understanding the three V's of big data (ZDNet)
Big data: More must-read coverage (TechRepublic on Flipboard)






 English (US) ·
English (US) ·